How Josh Albrecht is Starting an Independent AI Research Lab (PLUS: fine-tuning language models, Spotify's ML platform, and more...)
Feb 26, 2021 1:01 am
Hi !
As I mentioned last week, I'm collaborating with the MLOps Community to start a reading group focused on ML Engineering and ML Ops. So far over 120 people have expressed interest in joining and we're going to be starting up in the next two weeks. If you'd like to join us, click here and fill out the survey.
In this week's edition:
- Starting an Independent AI Research Lab with Josh Albrecht from Generally Intelligent
- Recent Advances in Language Model Fine-tuning
- The Evolution of Spotify's Machine Learning Platform
- Ways to Think About Machine Learning
- TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models
Starting an Independent AI Research Lab with Josh Albrecht from Generally Intelligent
"It seems much more likely for us to end up in a good spot if we're making intelligences that are similar to us and intelligence that we actually understand... Something that is really excited to support our values and do the things that people are excited to do and create material and emotional and intellectual abundance so that everyone can do what they're excited about."
Josh Albrecht is the co-founder and CTO of Generally Intelligent, an independent research lab investigating the fundamentals of learning across humans and machines. Previously, he was the lead data architect at Addepar, CTO of CloudFab, and CTO of Sourceress, which Generally Intelligent is a pivot from.
In this episode, Josh talks about pivoting from an AI recruiting startup to Generally Intelligent, an independent AI research lab. He also touches on how he defines general intelligence, what his lab is working on now, and how he creates the optimal research environment.
Click here to listen to the episode, or find it in your podcast player of choice: https://www.mlengineered.com/listen
If you prefer to read instead of listen, I've also written out the major takeaways from the episode on my blog, which you can find here.
Recent Advances in Language Model Fine-tuning
"Fine-tuning will continue to be the modus operandi when using large pre-trained LMs in practice... While pre-training is compute-intensive, fine-tuning can be done comparatively inexpensively. Fine-tuning is more important for the practical usage of such models as individual pre-trained models are downloaded—and fine-tuned—millions of times"
I've written previously that transfer learning is one of the most relevant research fields to ML engineers working in industry. And judging by the engagement this tweet got, many of you agree:
In his latest blog post, Sebastian Ruder provides an overview of the recent advances in methods for fine-tuning language models. He identifies five different categories of fine-tuning, when to use them, and the latest research for each one.
If you work with NLP, this is a must-read!
The Evolution of Spotify's Machine Learning Platform
"As we built these new Machine Learning systems, we started to hit a point where our engineers spent more of their time maintaining data and backend systems in support of the ML-specific code than iterating on the model itself. We realized we needed to standardize best practices and build tooling to bridge the gaps between data, backend, and ML: we needed a Machine Learning platform."
More and more companies are starting to see the value-add in machine learning. As adoption increases within an organization, growing pains are inevitable.
In this post on Spotify's engineering blog, the authors detail their 3-year journey iterating on their ML infrastructure, starting first with connecting existing workflows to common tools, then moving to TFX and finally to KubeFlow.
Ways to Think About Machine Learning
"So, this is a good grounding way to think about ML today - it’s a step change in what we can do with computers, and that will be part of many different products for many different companies. Eventually, pretty much everything will have ML somewhere inside and no-one will care."
I'm fascinated by how the future will be effected by the proliferation of machine learning. In this article, Benedict Evans, one of the smartest tech writers today, uses the metaphors of a washing machine, a relational database, and a horde of 10 year-olds to better align our thinking as to what ML enables.
Pair with Shreya Shankar's article on AI Saviorism
TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models
"We show that TeraPipe can speed up the training by 5.0x for the largest GPT-3 model with 175 billion parameters on an AWS cluster with 48 p3.16xlarge instances compared with state-of-the-art model-parallel methods."
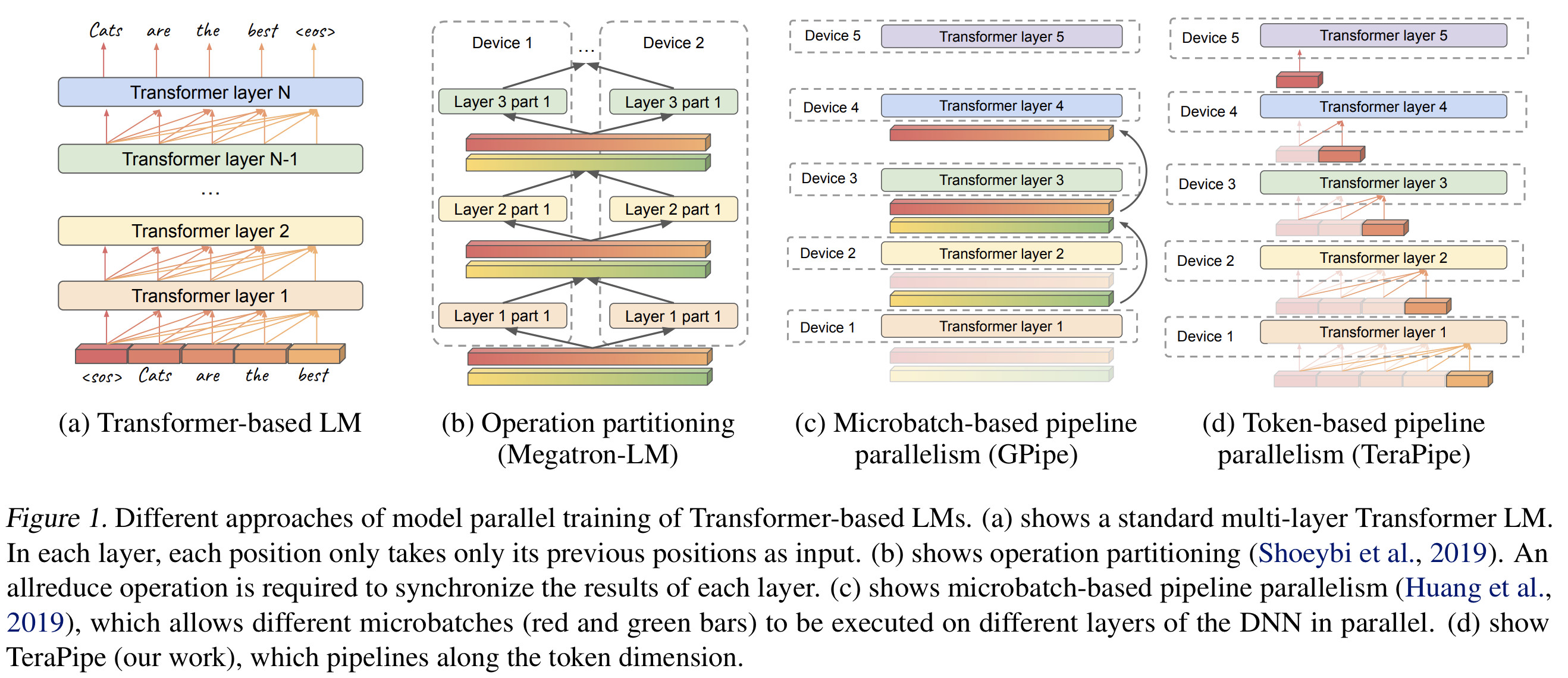
I've always enjoyed reading about unique algorithmic solutions to hard problems. Distributed training of huge language models is about as hard as it gets, and in this arXiv pre-print, researchers from UC Berkeley detail how they were able to obtain significant speedups by parallelizing across tokens in a single sequence through some clever partitioning and execution scheduling algorithms.
Thanks for reading and have a great rest of your week!
Charlie
P.S. If you're enjoying the newsletter, consider sharing it with a friend by forwarding it to them or having them sign up at this link: https://www.cyou.ai/newsletter