Managing Data Science Teams and Hiring ML Engineers (PLUS: Lessons from building AI systems for healthcare, recap of TWIMLCon, and more...)
Feb 12, 2021 4:01 am
Hi ,
"New year, new me!" was what I had planned on saying to introduce my new personal site. Unfortunately, it took about a month more than I had originally estimated, but better late than never! I plan on investing way more time into writing this year, and updating the design of my site for the first time since freshman year of college was a solid first step.
Over the next few months I'll be back-filling extended show notes for past podcast episodes (they currently only exist for episodes 16+) as well as writing a (not always ML related) blog post every week.
You can check it out by clicking here. Any and all feedback is appreciated! Just hit reply.
In this week's edition:
- Insights Into Effective Management, Hiring ML Engineers, and Driving Enterprise AI Adoption
- Building an ML System for Southeast Asia’s Largest Hospital Group
- James Le's TWIMLCon 2021 Notes
- Jax is all you need?
- Deep learning forecasted to create more economic value than the internet
Insights Into Effective Management, Hiring ML Engineers, and Driving Enterprise AI Adoption
Harikrishna Narayanan is the co-founder of a YC-backed stealth startup. He was previously a Principal Engineer at Yahoo, a Director in Workday's Machine Learning organization, and holds an M.S. from Georgia Tech.
In this episode, Hari discusses what it means to be an effective data science manager, how he thinks about hiring for machine learning roles, and what he's learned from driving ML adoption in a large organization.
If you prefer to read, I've also written out the major takeaways from the episode on my blog, which you can find here.
Building an ML System for Southeast Asia’s Largest Hospital Group
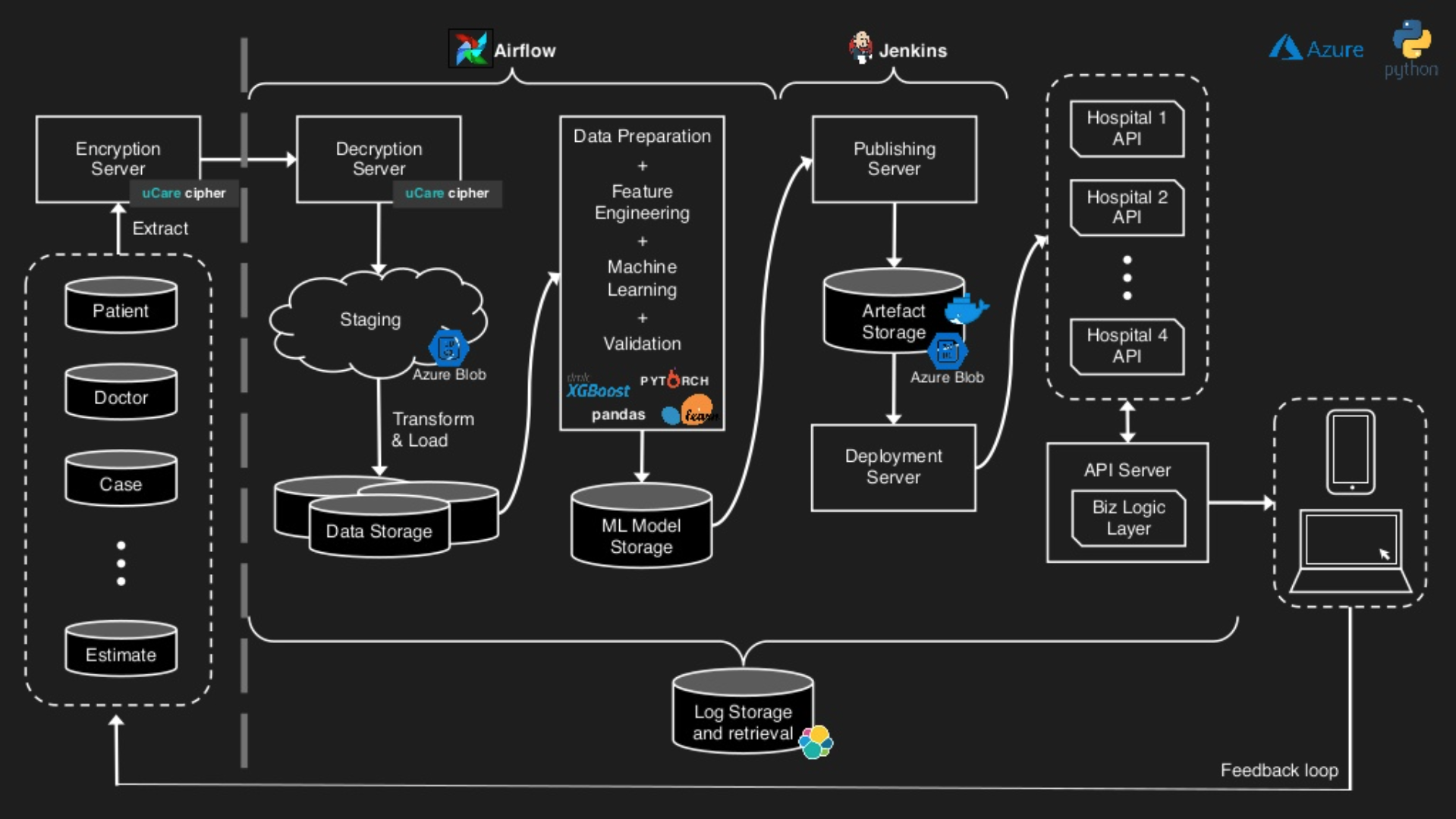
As I had mentioned in a previous edition, Data Talks Club has been hosting a free conference every Friday in February.
Last week, Eugene Yan, one of my favorite data science writers, gave an excellent talk on his experience building a machine learning system to predict hospitalization costs. Among the various takeaways from this project was that building useful data products is a team effort, to not assume anything about the data (boy, I've re-learned this one a few times!), and that machine learning itself is only a small part of the work.
I highly recommend you watch it, which you can do by clicking here.
In the past week, I also spotted his reply to Vicki Boykis' excellent question on Twitter:
James Le's TWIMLCon 2021 Notes
TWIMLCon is an annual MLOps and enterprise ML conference held in January. Talk topics ranged from case studies of companies like Spotify scaling their ML efforts to arguments for various new pieces in the ML Ops stack (feature stores, data catalogs, and more).
Fair warning, this is a very long post and to to be honest I haven't fully finished it. But from the sections I've read so far, James does a really good job highlighting the challenge, solution, and key takeaways without too much extra info.
If you weren't able to convince your boss to comp a TWIMLCon ticket (*cough* me *cough*), you should definitely check out this recap by clicking here.
By the way, James is also a fellow podcaster! He hosts Datacast, which aims to tell the career stories of data scientists, engineers, and researchers.
Jax is all you need?
I've highlighted Jax before, but in the past few weeks, three really interesting blog posts came out showing some of what's possible with the Google-borne framework:
- Evolving Neural Networks in JAX
- Exploring hyperparameter meta-loss landscapes with Jax
- Parallelizing neural networks on one GPU with JAX
While I typically warn against trying out every new library that emerges, adoption of Jax is growing both inside Google and out, and I wouldn't be surprised if it eventually goes on to challenge Tensorflow and PyTorch.
You can check out the Github repo here.
Deep learning forecasted to create more economic value than the internet
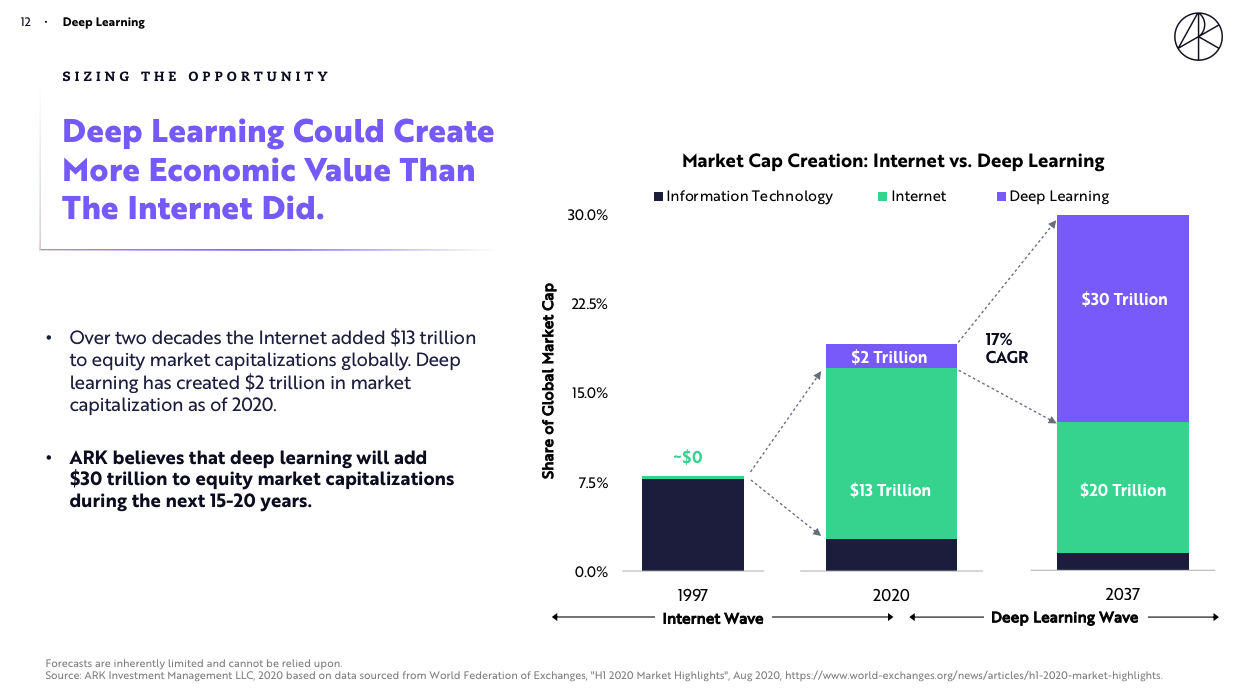
Ark Invest is an asset manager best known for its public ETFs focused solely on "disruptive innovation". They had a bonkers 2020, with their flagship fund ARKK returning over 152% (!).
They recently published their yearly white paper "Big Ideas for 2021", which highlighted deep learning as the number one most disruptive trend, forecasting that it will create more economic value than the internet (!).
"During the next decade, we believe the most important software will be created by deep learning, enabling self driving cars, accelerated drug discovery, and more."
I include this in here to remind you of the enormous potential that is still unrealized by this technology. If you're reading this, you're still relatively early to the field compared to what it will inevitably become.
Read the white-paper by clicking here.
Pair with Airstreet Capital's 2020 State of AI Report.
Thank you for reading and have a great week!
Charlie
 Oracle Integration Cloud (OIC) Training
Oracle Integration Cloud (OIC) Training